PDF OCR X is a free multi language OCR software for Windows and Mac OS which supports characters from over 60 different languages. Scanned text can be loaded (as image files) and then easily converted either into editable text files (.TXT extension) or PDF documents (.PDF extension). Text images that you load into PDF OCR X can be any of the 60 supported languages. Their characters are gonna be recognized from the images using OCR and then converted into either editable text or PDFs.
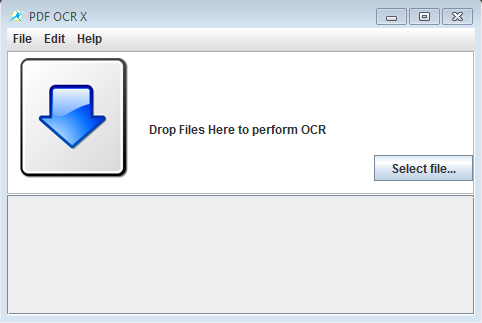
Interface of PDF OCR X doesn’t look like much at first, as you can see from the screenshot down below. You only get a Select file button in the bottom right, drag and drop zone in the middle and a standard menu in the top left corner.
Once that you add and select image that you’d like to see converted, additional window is gonna appear where you can tweak conversion settings and install additional languages if the selected scanned image is not in English which is the default language which is supported.
Key features of PDF OCR X are:
- Free and simple to setup: tweak everything in just a couple of mouse clicks
- Allows you to convert text into images using OCR – optical character recognition technology
- Supports over 60 languages: detects and converts.
- Can be used to convert both scanned images and PDF scans
- Works with all the common image formats: JPEG, BMP, GIF, etc.
- Cross platform: works on both Mac OS and Windows, all versions starting with Windows XP
Similar software: Free Online OCR, i2OCR, OnlineOCR.
Free version of this multi language OCR software only allows you to scan one page at a time. This means that if you have a PDF document that’s created from scanned images, you’re only gonna be able to scan one page at a time. Same thing goes for image files, only one can be processed at once. Here’s a few pointers to help you get started.
How to convert scanned PDF documents and images into text and PDF files using PDF OCR X: a free multi language OCR software
Open up an image file or a scanned PDF document by clicking on the Select file button or by dragging and dropping them onto the application window. Once you do that, the config window that we mentioned before is gonna show us.
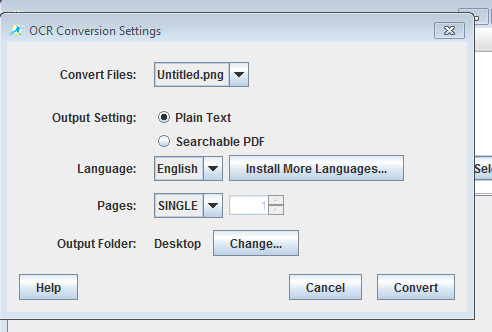
You can see this config window on the screenshot above. Most important setting here would be the language setting, where you need to select which language exactly the document that you’ve selected has.
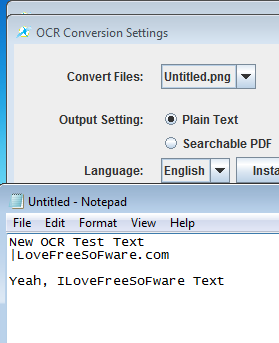
All the other settings are pretty much self explanatory. When you’re done setting everything up, click Convert and selected scanned document is gonna be converted into text.
Conclusion
Everything went OK when using PDF OCR X without any kind of problems. During our tests we noticed that not all of the characters are detected all the time properly, but that’s true about every software that exists out there. Give it a try and see how it goes. Leave comments in the comment section down below.
{kind=link}