In this tutorial, I will show you how to prevent your website data from being used for AI training, especially by Google and Open AI.
If you are running a blog or forum or some other kind of website where you publish a lot of content, then it’s probable that your content is being scraped and used for training various AI models or LLMs. But you can prevent that now, and I will show you how. To do this, there is no need to install plugins or subscribe to a service. You only have to make edits in the robots file.
With AI models growing more advanced every day, website owners are concerned about what happens to all the data bots collected from their sites. Now there’s an easy way to prevent certain bots from accessing and using your content without permission through a robots.txt file on your server.
Prevent your Website Data from being used for AI Training by Google:
Google recently announced that you can prevent Google’s AI systems from crawling content from your website and use it for AI training. Basically, you can now stop the Google AI bot from collecting data from your website.
Log into the control panel of your website. Or you can also use FTP to browse your site’s root directory structure. That’s where the robots.txt files live.
Open the robots.txt file and add these lines.
User-agent: Google-Extended
Disallow: /
The above code will prevent Google systems from crawling any part of your website and use or collect the content. But if you only want to prevent certain folders from crawling and scraping, then you can use this code instead.
User-agent: Google-Extended
Disallow: directory_name
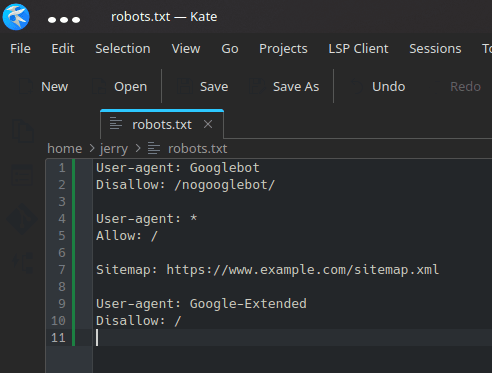
Save the changes now and from now on, Google’s AI bot will respect your privacy and your decision not allowing your website content to be used for AI training.
Prevent your Website Data from being used for AI Training by Open AI (GPT or ChatGPT):
Just like Google, OpenAI also announced quite some time ago that you can prevent the GPT bot from crawling on your website and use the content for training.
The process is exactly the same as above. You just have to use a different bot’s name. So, just again open the robots.txt file and add the GPT bot like this and block it from accessing, crawling, or scraping your websites.
User-agent: GPTBot
Disallow: /
If you only want to prevent specific directories from being crawled or accessed, then use the following format for the crawler.
User-agent: GPTBot
Disallow: directory_name
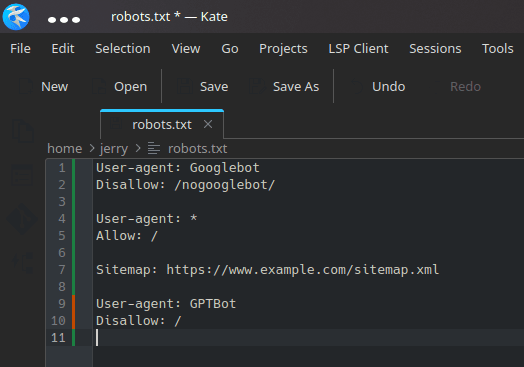
Save the changes and drop all the caches in case you are using a caching system such as Cloudflare or WordPress cache plugins. Once the changes take effect, the AI bots of Open AI will not consider your website for AI training.
Closing words:
By adding “Google-Extended” and “GPTBot” to your site’s “robots.txt” file, you can block Google’s AI systems and bots of other large language models from crawling and ingesting content for computational linguistic research or training purposes. So, just follow the methods I have explained here and sit back, relax. I am sure in the future there will be more such methods will be available for the coming AI models.
{kind=link}