This tutorial explains how to extract text from multiple scanned PDF files together using OCR. Pdf2ocr is a simple command line tool to easily convert an image-only PDF to text easily. It supports multiple languages and takes a single or a directory of PDF files to convert them to text. It creates a separate text file corresponding to each PDF files that it finds in the folder. It works very accurately and converts each page in PDF to text quickly. However, it may fail to extract to text if the font of the text on image is fancy. Otherwise, it works very perfectly on the straight text no matter what color is in the background.
There are some PDF to text converter software. But they only process text based PDF files to text. You cannot use them to extract text from non-searchable PDF files or scanned PDFs. That is where Pdf2ocr comes in handy. You can run it directly from the command line and you can use it in your applications if you are a developer.
How to Extract Text from Multiple Scanned PDF Files Together Using OCR?
Pdf2ocr is a very nice command line tool to quickly convert multiple non-searchable PDF files to text. There is just a simple command that you need to execute on your PC to get text out of a single or multiple PDFs. Also, Pdf2ocr is an opensource tool so you can enhance it further if you have the relevant skills.
Here are some easy steps to extract text from multiple scanned PDF files together.
Step 1: Download the repository of Pdf2ocr from here. Extract it some place of your choice and then open command prompt in the same folder.
 Step 2: You can either place the source PDF files in the same folder or you can keep them where they are. The advantage of keeping source PDF files in the directory of Pdf2ocr will be that you will not have to append there path in the command. You just need to enter the name of the PDF files.
Step 2: You can either place the source PDF files in the same folder or you can keep them where they are. The advantage of keeping source PDF files in the directory of Pdf2ocr will be that you will not have to append there path in the command. You just need to enter the name of the PDF files.
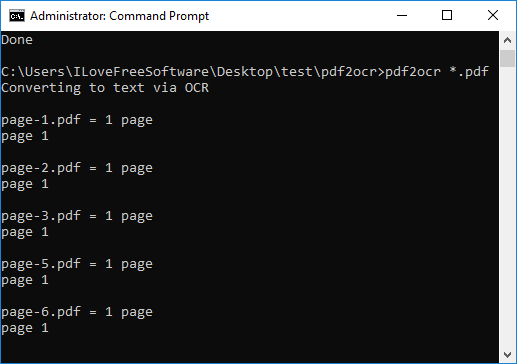
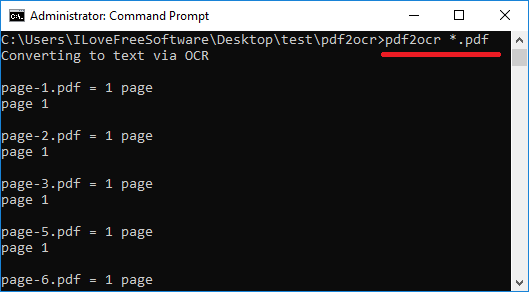
Step 3: Now, run this command to start converting the PDF files to text. After it finishes, you will see that it will leave the text files corresponding to each PDF file in the same directory in which the source PDF files were.
pdf2ocr "path to PDF file or the directory"
to convert all PDFs in current directory: pdf2ocr *.pdf
All the above steps will help you to extract text from multiple scanned PDF files together using OCR. And the Pdf2ocr tool does that in an easy way. If you have an idea how to use command line tools in Windows, then you will like it.
Final thoughts
Pdf2ocr is a simple and useful command line tool to easily extract text from multiple scanned PDF files together using OCR. You just need to run a simple command to get the text file corresponding a PDF file. So, if you have plenty of image-only PDF files, then you can use this tool to extract text. And the steps that I have mentioned above will help you.
{kind=link}