Buzz is a free desktop app that is based on OpenAI’s Whisper. It can transcribe audio to text automatically with ease. It has several models and you just speak into the microphone and it will convert it to text in almost real time. This is a completely open-source tool and it runs on Windows, macOS, and Linux.
The machine learning model that it uses underneath is very powerful. And by piping the audio system to microphone, you can transcribe songs and videos to text automatically as well. You just launch it and then it will start listening to audio from the microphone and will convert it to text for free.
Apart from transcribing audio, it can work in translation mode as well. In that case, you will only have to select the target language and then it will take care of the rest. However, for now, it supports only English language as input. You can only translate or transcribe spoken English words. But I hope that they add support for more languages in the later updates.
OpenAI launched Whisper a few days ago. Wisper is an open-source neural network that offers human level accuracy as well as robust experience on English speech recognition. It is fairly new and thus I am hoping that they will add more strong language support in the coming updates.
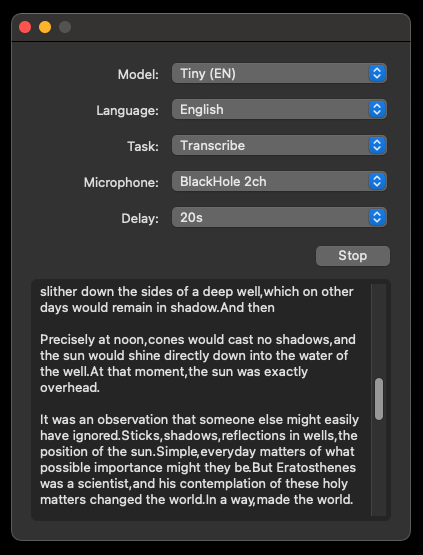
Free tool to Convert Audio to Text using Whisper by OpenAI: Buzz
Buzz is available on GitHub. It is written in Python. So, you can either run it directly from the source. Or, you can use the self-contained binary releases that the developer of this tool has provided.
If you decided to go with source, then you will need Python and poetry library installed. Afte that, you just run this command to install all the required dependencies and virtual environments.
poetry install
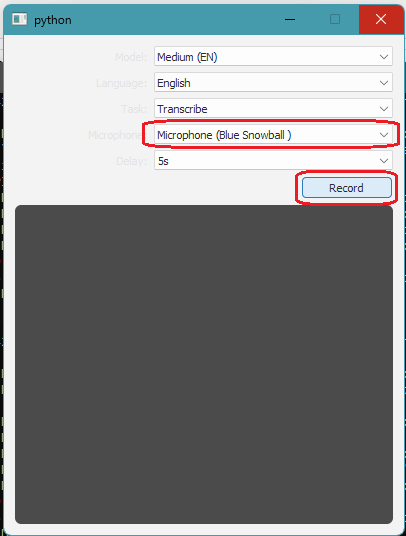
For simplicity, you can just download the binary release and run it directly. Releases for Mac, Windows, and Linux are available. Here I am using Windows version, so, you just download it and run it directly. It is quite heavy software so I will recommend you to try it on a computer with high hardware configuration. The very first thing you have to do is select the mic and specify the mode. By default, it runs in transcription mode.
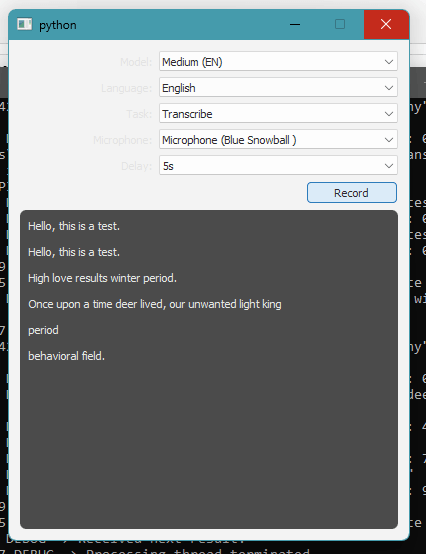
Now, you just let it start. For the first time when you run it, it will download the model in background. So, the first run will be a bit slower. After it is ready, you only need to hit the Record button. After that, you can start speaking and the text will appear in the editor. The transcribing process also depends on a number of factors such as delay.
For more information about the different models, refer to the following table:
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
You can now keep using this software in this way and do speech to text. The accuracy is fair. But it is not smooth as voice typing of Windows 10,11 and or Speechnotes website. For now, it just works and you can use it to test the accuracy and usability of OpenAI’s Whisper.
Closing thoughts:
Whisper is an amazing neural net for speech to text. As a developer or programmer, you can use it to build software and apps that need speech to text functionality. The accuracy is good but the speed and smoothness is missing from now on. But that is just the limitation of the GUI and not of the model itself. I hope they improve the UI in the coming updates.
{kind=link}