In this post, I will talk about how to extract tables from PDF using a free command line tool. The tool I am going to use is called, Camelot. You can easily install it on your PC using Python and then use that to extract tables from a PDF file. It lets you save the tables in CSV, HTML, and JSON format. And you can use it to extract tables from specific pages of a PDF file as well. It depends on some external tools which I will mention later. You just have to run a simple script to get tables from a specified PDF.
We have covered some free software to extract tables from PDF already. If you like command line tools to do stuff then you can use this tool, Camelot to extract tables from a PDF. It intelligently identifies tables in the input PDF file and then you can save that. Also, if you want to print that on console then you can do that. To use it, you just have to specify the PDF file’s path in the script that I will mention in the below post.
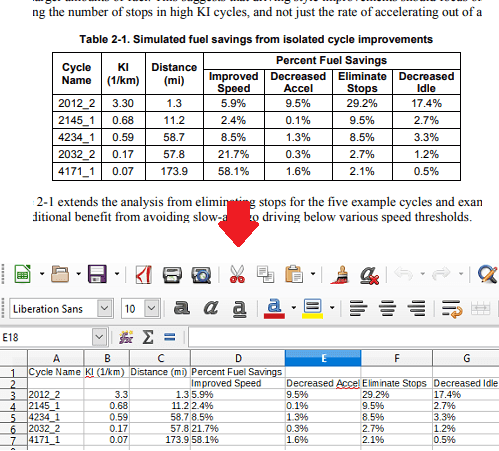
How to Extract tables from PDF with this Free Command Line Tool?
If you have ever used Python it will be very easy for you to understand, so, make sure that you have Python installed. After making sure that Python is installed then you have to install GhostScript and ActiveTCL. After you have installed these three, you can install Camelot using PIP. See the following steps.
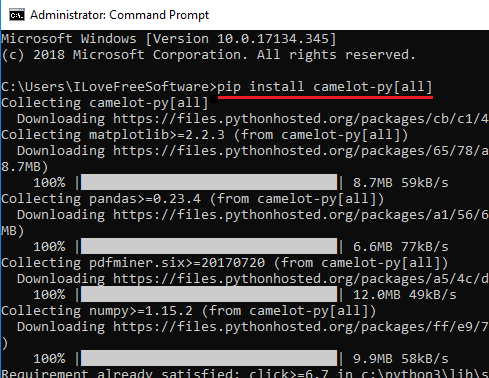
Step 1: Run the following command in command prompt to install Camelot. You can ensure the installation by running the “camelot –help” command.
pip install camelot-py[all]
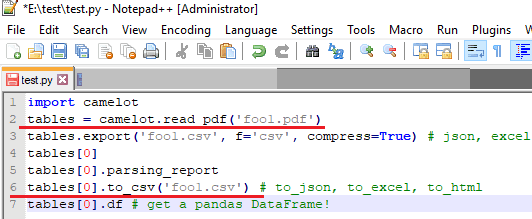
Step 2: Now, copy this script then replace “PDFPath” with the actual PDF path on your PC. Next, save the script as “test.py” file or you can give it any name that you want.
import camelot
tables = camelot.read_pdf('PDFPath')
tables.export('foo1.csv', f='csv', compress=True) # json, excel, html
tables[0]
tables[0].parsing_report
tables[0].to_csv('foo1.csv') # to_json, to_excel, to_html
tables[0].df # get a pandas DataFrame!
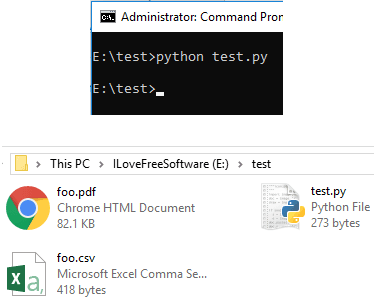
Step 3: Open a command prompt in the folder where you have saved the “test.py” file. Next execute the script and then it will save the table from the supplied PDF file in a CSV file. The CSV file that it creates will be saved in the current working directory.
python test.py
Step 4: You can use the script in the same way to extract the table from multiple pages then you will have to define them on line 2. In the “camelot_read_pdf” method, you can append page numbers or page ranges as well. And after running the script, it will save the table from each page in a ZIP file.

In this way, you can use this powerful and intelligent command line tool for PDF table extraction. You can use it to process any PDF file to extract tabular data like a pro. At first, the process may seem ambiguous one but once you use it, it will be a whole lot easier for you to use it next time.
Final thoughts
Camelot is a powerful and a nice command line tool for you to extract tables from PDF. You can easily use it to extract tabular data from all or specific pages of a PDF file. This is an open source application as well whose code you can find on GitHub using the link that I have mentioned above. If you need a command line tool to extract tables from scanned PDFs then it will work on those too. And you can easily save the tabular data to a CSV, HTML, and JSON file by simply executing a small script.
{kind=link}