Bark is a free and open-source text to audio converter AI model that allows you to generate speech, music, and sound effects. It even supports voice cloning that you can try. Right now, you can only try the version hosted on Hugging Face and then analyze its output. If you find it to be useful, then you can just grab its source code and then host it anywhere you like.
Bark is probably the only AI model available out there that can generate audio from text. Even Google announced one similar AI model a while ago but that is yet to be launched. So, if you use AI particularly for audio generation then you are going to like Bark. It supports contextualized prompts with additional context and music notes so that it will know what you want to do. You can also make it generate speech in the voice of some other person.
You can also learn more about Bark in this Twitter thread if you want to.
AI allows you to create realistic voices, music, sounds.
But most text-to-audio AI tools costs around $12/month.
Here's a free AI tool to start creating realistic voices just with text: 👇
— Barsee 🐶 (@heyBarsee) April 30, 2023
Free Text to Audio AI Model to Generate Speech and Music: Bark
As I mentioned it already that it is open source, you can quickly grab its source code here or simply take a look at it. For now, it has support for 13 languages but support for more languages is coming soon in the later updates. Some of the well-known supported languages in this model are:
- English (en) ✅
- German (de) ✅
- Spanish (es) ✅
- French (fr) ✅
- Hindi (hi) ✅
- Italian (it) ✅
- Japanese (ja) ✅
- Korean (ko) ✅
- Polish (pl) ✅
- Portuguese (pt) ✅
- Russian (ru) ✅
- Turkish (tr) ✅
- Chinese, simplified (zh) ✅
Now, here is the link to the model hosted on Hugging Face that you can try. It can be slow in generation, but it will work. It is kind of a proof of concept but if you want to run it in its full potential then you can grab the source code and run it after following the installation instructions (required heavy hardware requirements). The Hugging Face interface looks like this.
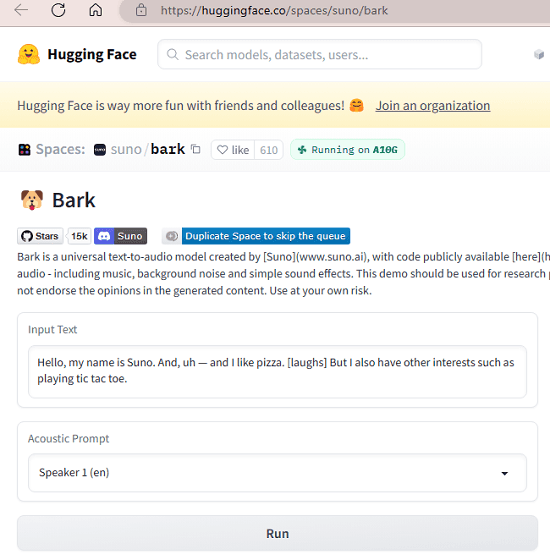
Enter the prompt in the box, or you can also run the example prompt given there already. Just select a speaker from the list and then go right ahead. Click generate and then it will produce the output speech in a few seconds.
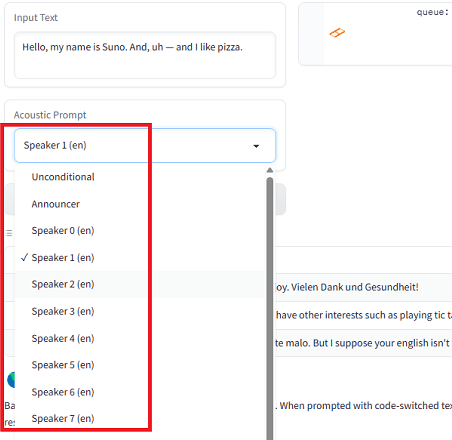
In the same way, you can generate the music or sound effects. Since the speech generation is the same process too, so, you can simply distinguish between speech generation and music generation by adding notes. See the example below and how the music notes are inserted in it.
♪ In the jungle, the mighty jungle, the lion barks tonight ♪
In the normal text input, you can insert some symbol to add extra effects such as laughing, clearing throat, etc. Here is the list of some supported non-speech sounds that you can opt to include in the final speech. They are being updated daily, and you can also recommend your own in the Discord server of Bark.
[laughter][laughs][sighs][music][gasps][clears throat]—or...for hesitations
An example: Hello, my name is Suno. And, uh — and I like pizza. [laughs]But I also have other interests such as playing tic tac toe.
See the placement of non-speech components in the speech generation.
In this way, you can make use of this free and powerful text to audio generation model. Convert text to speech, clone voices, generate music, and sound effects. The process is easy and Hugging Face interface makes it even much easier to use. Also, you can host it on your own server or PC if you have the right hardware requirements.
Closing words:
If you are looking for a free to use AI tool that can generate music, speech, and sound effects from description the Bark is the number one tool out there to do it. With this, you can generate voiceovers for your videos, podcasts, and even audio books. I liked that fact that it is multilingual and offers various configuration options to produce perfect output.
{kind=link}