In IT terminology, a Parser is a compiler program that analyses the syntax of certain selected data and then breaks it down into smaller discrete elements so that it can be easily translated into another language. For example, an HTML Parser will take in HTML code and extract important information from it like the title of the page, paragraphs (body) of the page, headings, links and more.
In this article we will be discussing about Content Parser, that is a free online tool that anyone can use to extract (parse) Plain Text, Markdown Language or HTML from websites that basically contain heavy content. The link for this application is available at the end of this article.
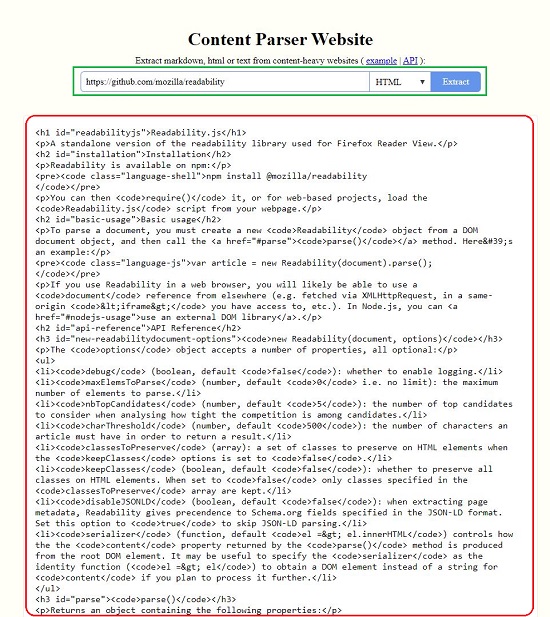
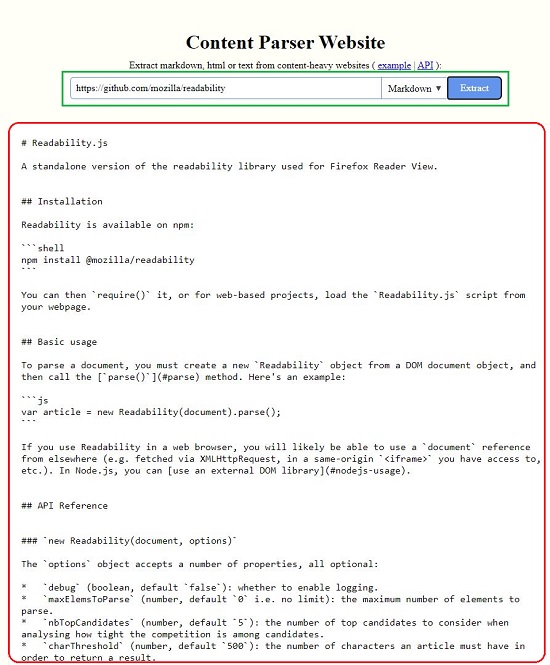
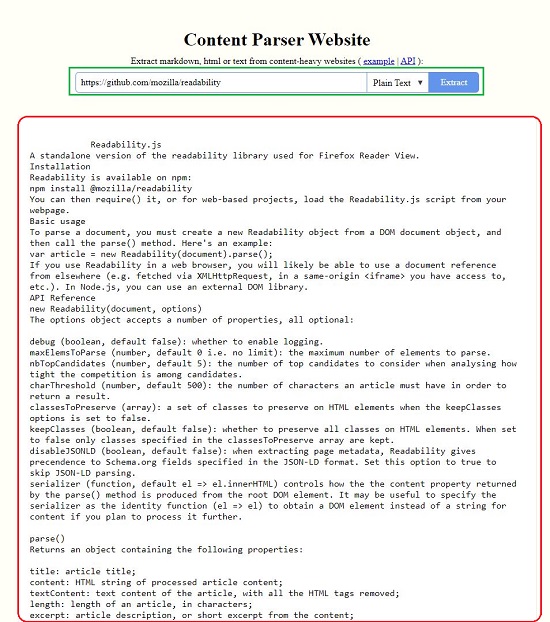
All that you need to do is type or paste the URL of the webpage from where you want to parse the data (information) and choose the type of extraction such as Markdown, HTML or Plain Text. Click on Extract and the parsed content will be displayed in hardly a few seconds.
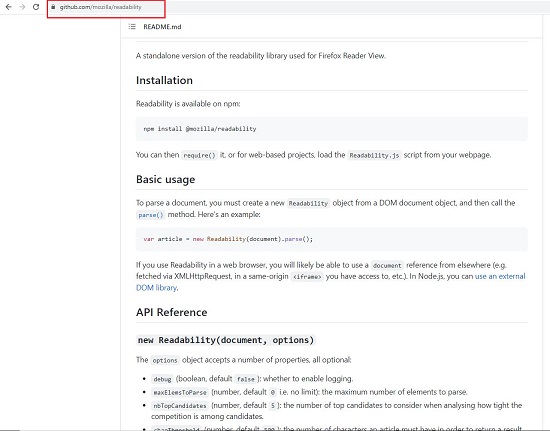
See the first screen shot below which depicts a repository page from the popular GitHub website. Then see how the content of the page is Parsed (Extracted) in all the three formats.
Closing Comments:
After testing for a while, I felt that this is a good online tool to easily parse the content of any website in multiple formats such as HTML, Markdown and more. This makes it easier for you to carry out a translation of the website for linguistic, formatting reasons and more.
Click here to navigate to Content Parser.
{kind=link}