Do you wish to figure out if you can run a specific LLM on your GPU? Are you confused about what quantization should be used to fit any model on your GPU, what is the maximum content length that it can handle, the type of finetuning it supports, and more including what precisely is consuming your GPU memory when you are training the LLM. If you are being challenged with the above uncertainties, then we have got a solution for you named GPU Poor.
GPU Poor is a free open-source, online tool that enables you to find out the GPU Memory required for the training & inference of Large-Language AI Models (LLM) and provides you the breakdown of where it actually goes. GPU Poor supports Quantization (GGML / bitsandbytes) inference frameworks (vLLM / llama.cpp / HF) and QLoRA.
Al that you are required to do is input the Huggingface Model ID and a few other parameters as told below and GPU Poor will tell you how much memory will be required for the chosen GPU along with the breakdown.
Working:
1. Click on this link to navigate to GPU Poor. You are not required to register or sign up for any account to use this tool.
2. Type the Huggingface ID or the Model size (in Billion) in the respective boxes. You can also upload the model config (JSON) file by clicking on the corresponding button.
3. Next, use the ‘Training or Inference’ drop down menu to choose the respective option such as Inference (Huggingface), Inference (GGML), Training (Huggingface) etc. Also select the Training Method (Full, LoRA, qLoRA), Optimizer (ADAM / SGD) and the type of Quantization technique like BNB INT8, GGML QK8_0 and many more from the respective drop-down lists.
4. Finally, input the Context length, Batch size (only for training), choose the GPU from the list and click on the button ‘Find Memory Requirement’.
5. GPU Poor will instantly display the Total Memory required along with the Breakdown in the form of Activation memory, Grad & Optimizer memory and other overheads.
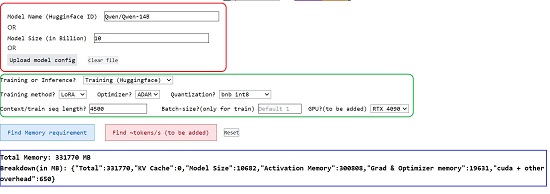
You must remember that the memory requirement values shown by GPU Poor are approximate and may vary by 500 MB to 1 GB based on the GPU, Model and other inputs.
Closing Comments:
GPU Poor is fine open-source tool that can be used to evaluate how much memory is being used for the training / inference of Large Language Models. It also gives you the breakdown of the memory by showing where and how much of it is being consumed.
Click here to navigate to GPU Poor. To access its Source Code on GitHub, click here.
{kind=link}